
Generative Adversarial Networks (GANs) were first introduced in 2014 by Ian Goodfellow in his paper “Generative Adversarial Nets.” This paper presented the GAN framework, which consists of two neural networks called the generator and the discriminator. The generator takes random noise as input and outputs a generated image. The discriminator takes both a generated image and a real image as inputs and tries to determine which is real and which is generated. Their training process can be likened to a ping-pong game, with the generator trying to produce images that fool the discriminator, and the discriminator is trying to identify which images are generated.
Prior to 2017, normalisation methods within GANs still used Batch Normalisation. This normalisation scheme was initially introduced to help train Convolutional Neural Networks (CNNs) by normalising each of the channels in each batch. In batch normalisation, channel-wise normalisation is performed using the formulas below. This works well in CNNs by ensuring a consistent channel mean and variance, resulting in a more stable training process and improved gradient flow.
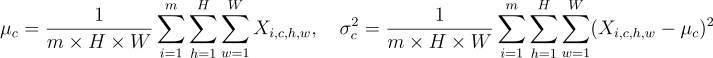
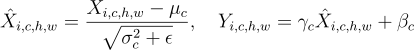
Here, c denotes the channel (also known as the feature map), m is the batch size, and H and W represent the height and width of the image.
Batch Normalisation in CNNs has been proven to be effective but in GANs it has introduced limitations. An ideal GAN should produce a wide range of outputs. However, when Batch Normalisation is applied, it often results in samples with a similar distribution across the batch, reducing the uniqueness of each sample. This phenomenon is known as mode collapse.
Mode collapse occurs when the generator struggles to produce a diverse range of images. Consequently, the generator learns to produce a limited set of images that can fool the discriminator, rather than focusing on generating a diverse array of images.
Another issue with Batch Normalisation is that it creates small dependencies between the sample channels, as each sample impacts the scaling applied to the channel. This results in inconsistent normalisation, which is not optimal for any individual image in the batch.
To address these issues, a new type of normalisation is needed. This new normalisation is called Instance Normalisation (also known as Contrast Normalisation). Instance Normalisation was introduced by Dmitry Ulyanov in his paper “Instance Normalization: The Missing Ingredient for Fast Stylization” as a way to improve the performance of artistic style transfer.
The goal in artistic style transfer is to recreate the style of one image within the context of another. For example, the generator would take the art style from a painting and apply it to a portrait. This produces a portrait with the given art style. The networks that solve these problems are called Style Transfer Networks. In these networks, the painting is referred to as the style image, and the portrait is the content image.
To avoid the effect of samples impacting each other’s output images, Instance Normalisation normalises each channel individually using the following formula:
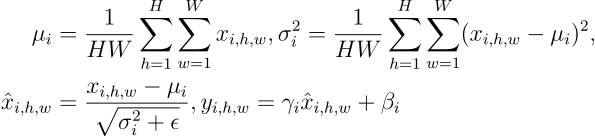
Here i denotes the ith channel, and H and W denote the image height and width, respectively.
This normalisation is crucial in Style Transfer Networks which feed both the content image and style image into the same network. Without Instance Normalisation the normalisation would be inconsistent as the content image would impact the normalisation of the style images and vice-versa. Dmitry mentioned this in his paper as he found that the larger the batch size was used, there would be a larger drop in performance of the network with Batch Normalisation.
The image below should help understand the difference between the normalisation schemes.
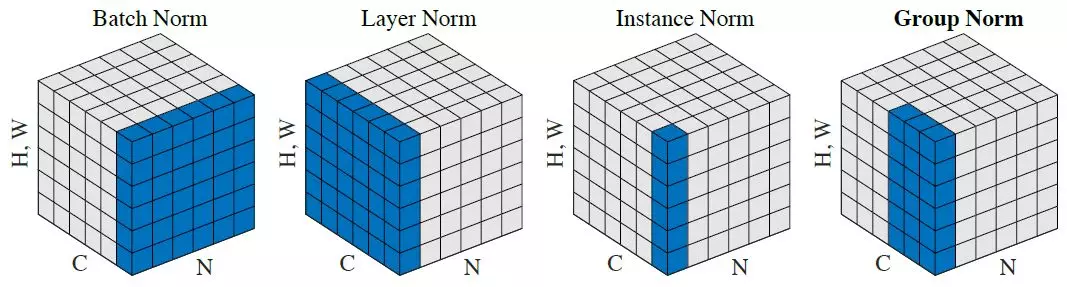
SyncedReview (2018) Facebook Ai proposes group normalization alternative to batch normalization, Medium. Available at: https://medium.com/syncedreview/facebook-ai-proposes-group-normalization-alternative-to-batch-normalization-fb0699bffae7 (Accessed: 22 June 2024).
This article covered the introduction of Instance Normalisation in Neural Networks and its preference over batch normalisation in the domain of GANs.
References
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. https://arxiv.org/pdf/1406.2661
Ulyanov, D., Vedaldi, A., & Lempitsky, V. (n.d.). Instance Normalization: The Missing Ingredient for Fast Stylization. https://arxiv.org/pdf/1607.08022